

Our TL;DR
- Most production tokens are no longer consumed by interactive AI applications. They come from background agents running in loops, with no humans at the keyboard.
- The key performance indicators for Interactive AI applications are interactivity SLO metrics such as TTFT, TPOT, ITL. The KPI for Async AI is tasks completed per dollar. This metric covers both faster job completion and higher fleet throughput.
- Today's inference stack was built for interactive AI applications. But Async Agent work is long-horizon, idle-heavy, and read-heavy. The mismatch is at the core of inference bottlenecks.
- At cluster scale, inference is no longer a request-response service. It is the continuous allocation of compute, memory, and bandwidth across a moving workload.
- Solving this means treating the cluster as one machine, the workload as a moving target, and adapting, in-flight, every scheduling, routing, and memory choice. This is Impala’s approach, which treats inference as a high performance computing problem.
AI workloads have changed. The stack remained the same
The dominant consumer of enterprise AI applications in 2026 is no longer a person interacting with chat. It is a harness that runs in loops, calls tools, branches, retries, summarizes, fans out subagents, and halts on its own. We call these workloads async AI, and the running software an agentic system. The harness is the loop that calls the model and tools.
- Spotify reports that ~50% of recently merged pull requests are agent-authored.
- OpenRouter measures average prompt length quadrupling in 20 months, with reasoning models now moving more than half of all tokens.
- Anthropic reports that agentic workflows use roughly 4× the tokens of a typical interactive request; multi-agent systems use 15×.
Most of those tokens are produced in parallel, in the background, with no human waiting at the end of each task completion.
The metric that matters: tasks per dollar
Interactive AI applications such as chat, copilots, anything with a human reading tokens as they stream are optimized against interactivity SLO metrics: TTFT (time to first token), TPOT (time per output token), ITL (inter-token latency), and end-to-end per-request latency.
When we think of Async AI, those targets are still real, but since a human is no longer waiting for a chat response, the end goal becomes different: latency, which humans are sensitive to, is less of an issue. Cost and actual performance matter more, especially given the fact that Async AI is token hungry.
The async AI economic contract is made of two factors the runtime should maximize at the same time:
- Economic value per token. How much real work each generated token actually advances.
- Throughput: tokens per second, fleet-wide. How fast the cluster turns the work out at scale.
The combined metric is completed agent tasks per dollar. On the side of the receiving agent, the target is lower job completion time (JCT, wall-clock from submit to done) at lower cost. Faster and cheaper, not faster-or-cheaper.
What async AI looks like under the hood
An agent's run is a trace (a rollout): a directed sequence of model calls, reasoning blocks, and tool executions where each step's output appends to the next step's input.
Two properties of that shape are load-bearing.
Long-horizon and idle-heavy. Production studies report a mean of about 20 tool steps per trace, the tail reaching more than 200 tool steps, and tool-call latencies exceeding hundreds of seconds, with idle waiting accounting for up to 58.2% of total delay. A 2–30 second tool-call gap is long enough to age a prefix out of HBM under default eviction. Without state retention across the gap, every resume results in a full prefix recompute.
Read-heavy. Coding-agent traces routinely show prompt-to-completion ratios around 70:1, with cumulative KV cache read/write ratios an order of magnitude higher. System prompts and tool schemas dominate input mass. The most valuable object in the stack is the prefix every step re-reads and not the tokens just produced.
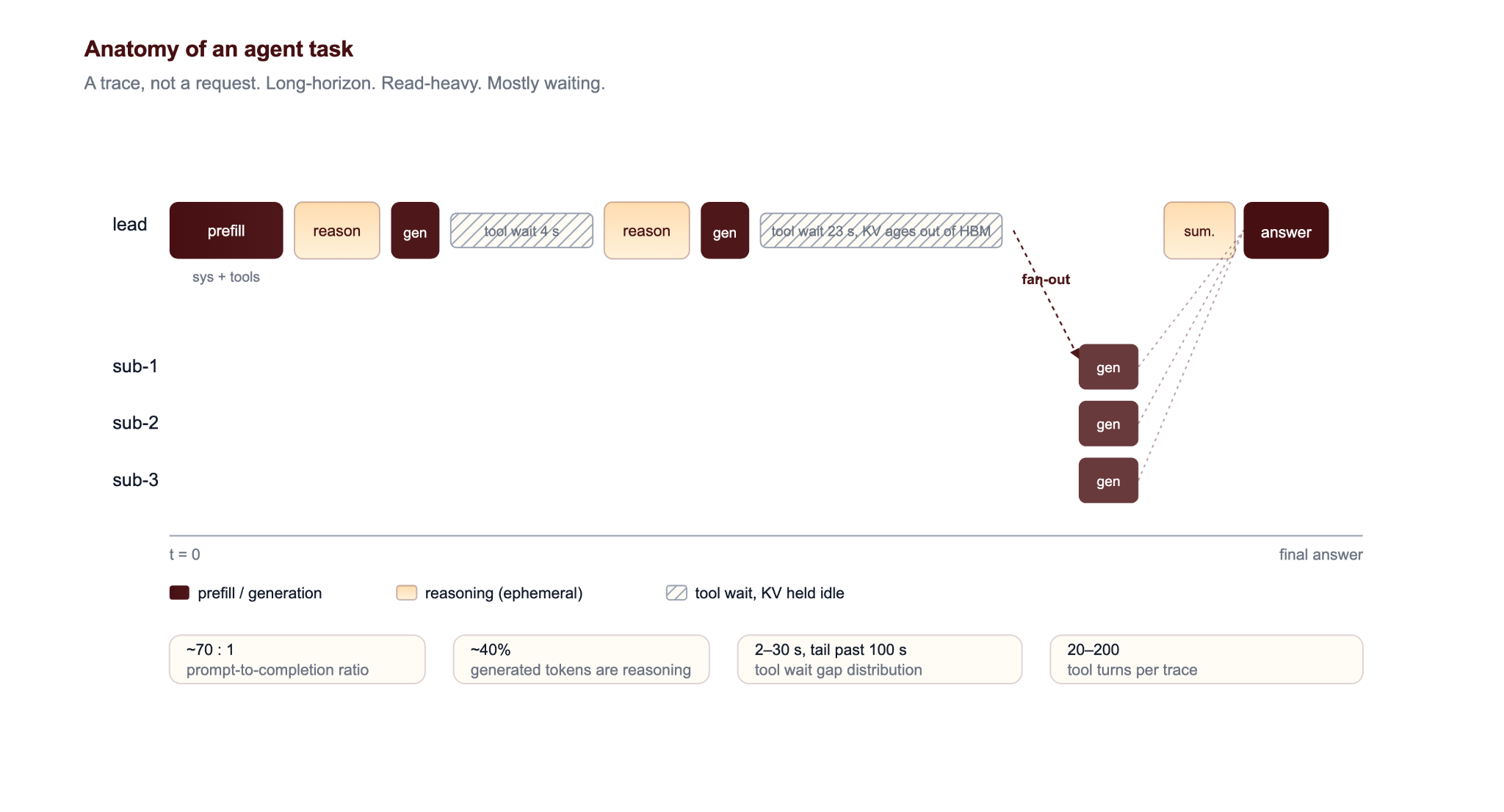
Why the current inference stack falls short
Today's inference stack assumes independent requests, stationary traffic, and the interactivity SLO metrics as the optimization target. Run a trace against that contract and three failure modes emerge at once.
Three ways the interactive-AI stack breaks on traces
The unit, the placement, and the cache are all wrong, in three different ways.
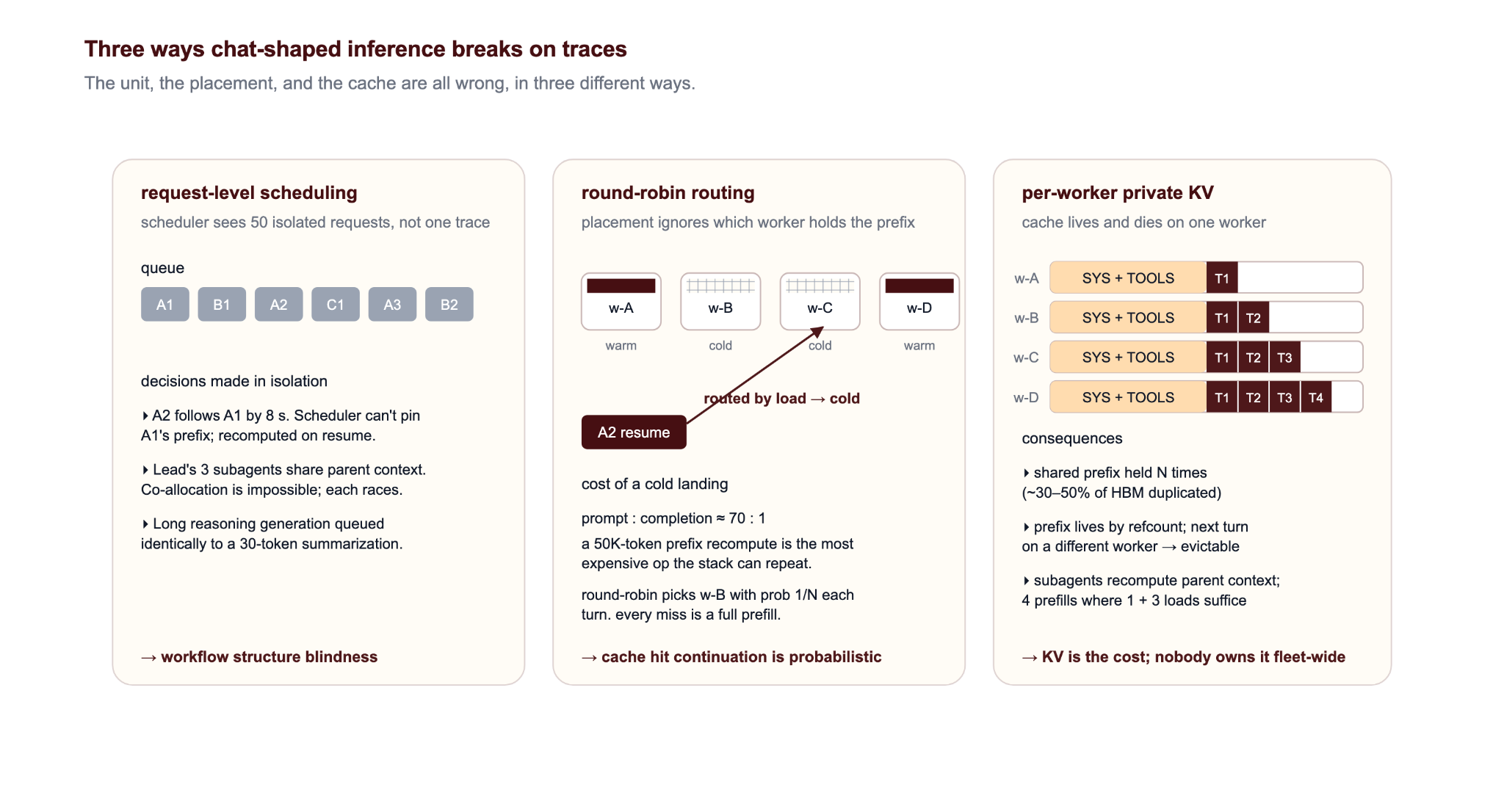
- Scheduling: trace vs request
Fifty model calls from one agent are scheduled as fifty independent requests, where the trace should have been scheduled instead. The scheduler cannot pin a prefix that is due back in eight seconds, cannot gang-allocate a fan-out, cannot rank a long reasoning generation against a 30-token summarization. Astraea reports up to 25.5% lower average JCT from segment-aware scheduling alone. We expect to have JCT up to 10X faster by taking a different approach.
- Placement: routing doesn't account for cache locality
At a 70:1 read-to-write ratio, a 50K-token recompute on a cold worker is the most expensive thing the stack can repeat. SGLang reports up to 6.4× throughput from prefix-aware routing; Mooncake's disaggregated KV pool shows comparable TTFT wins. Most production routers see neither — default round-robin placement holds cache hit rate around 30–40% on multi-worker agentic fleets.
- Caching: KV cache is not shared
The same parent prefix sits replicated across N workers. Bursts make hot blocks evict each other. A uniform LRU treats a system prompt re-read every step the same as a one-shot tool result. Multi-base, multi-LoRA fleets compound all three: LoRA adapters (small swappable fine-tunes) layer over different bases per task or tenant, locality fragments to (model, adapter, prefix), adapter swaps stall the GPU mid-batch, and weights and KV contend for HBM in tens-of-millisecond demote-promote cycles. With Impala's runtime, a fleet-wide KV index dedupes shared prefixes and reuse-weighted eviction keeps them resident through 5–10X the burst pressure a uniform LRU survives, so the gain compounds rather than washes out under load.
5. Async AI done right
With the emergence of async AI we need to redefine what successful inference looks like. At agent scale, inference is the continuous allocation of compute, memory, and bandwidth across a distributed compute fabric, and the runtime that wins is the one that treats it that way.
The cluster is one machine. The workload is a moving target. Every scheduling, routing, and memory-placement decision is re-made against a live picture of what the fleet is actually doing, not a rigid configuration which assumes a "happy middle".
Done right, the engine recovers the structure of the work from in-workload signals, rather than waiting for the harness to describe it. Everything else — the scheduling, the routing, the KV lifecycle — follows from that one move.
Five design moves do most of the work, and the gain is multiplicative. Scheduling, cache-aware placement, and fleet load balancing all decide against the same live trace state, on the same cycle, in the same control loop.
An inference runtime that adapts to the workload it is actually serving
The fabric is the resource. The trace is the unit. The decisions are continuous.
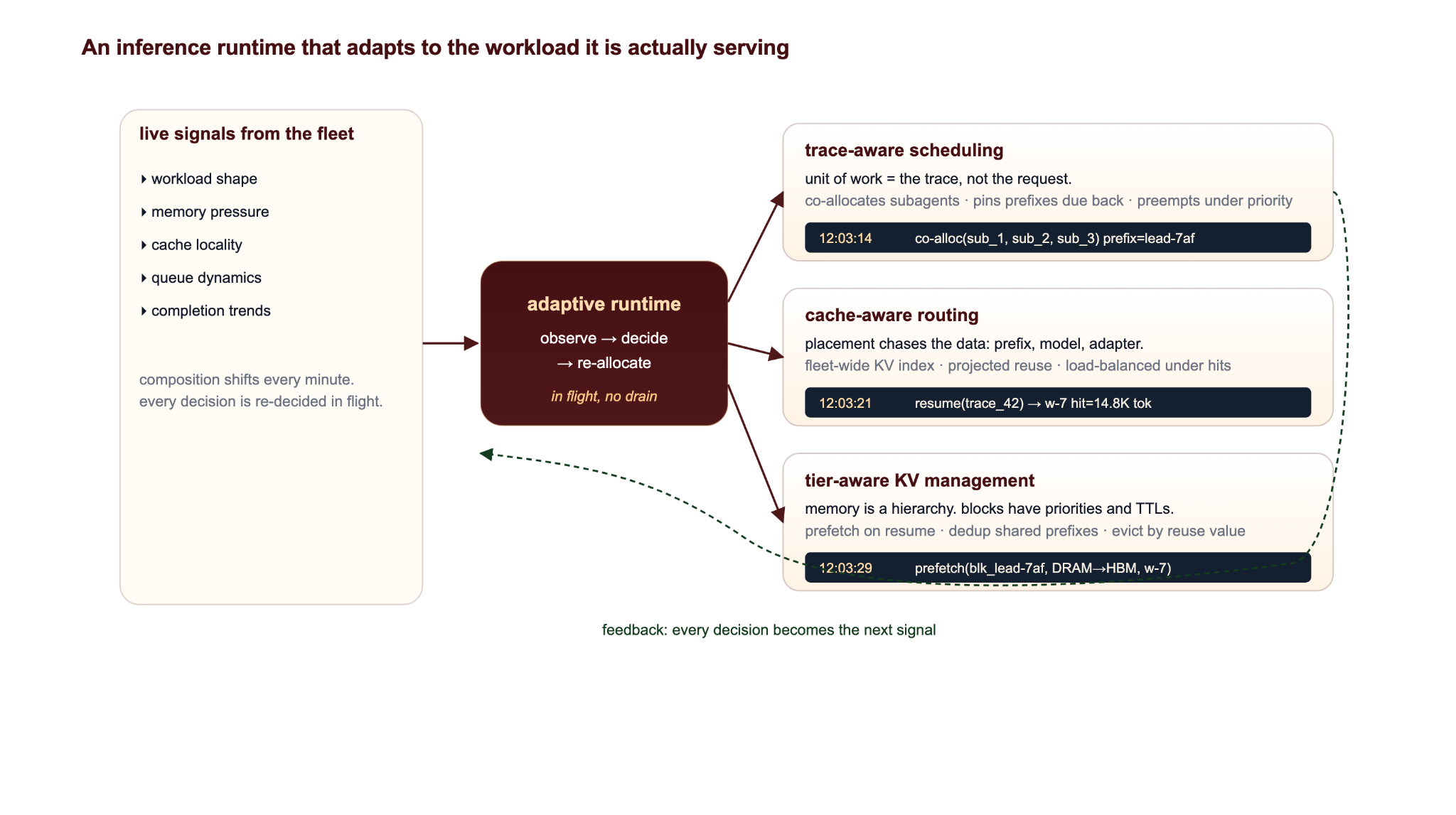
Make the trace the unit of work
The scheduling unit lifts from request to trace. Trace identity is reconstructed inside the engine from signals it already holds — prefix-hash overlap, request-arrival cadence, fan-out structure, model selectors on the request envelope. With trace identity in hand, the scheduler pins a prefix whose resume is due in eight seconds, gang-allocates fan-outs grounded in a parent context, defers background traces whose resume is far out, and ranks a long reasoning generation differently from a short summarization. Approximate SRTF (shortest-remaining-time-first — prioritize jobs near completion) over inferred trace state clears the head-of-line blocking that drives JCT tail.
Make placement a cache decision
The routing key lifts from (load) to (prefix, model), scored against a fleet-wide KV index of what every worker holds and how recently it was touched. With prefix reuse dominant, routing decides between a 14K-token cache hit and a 14K-token recompute. The router switches policy as the mix demands — strict locality when hits are abundant, fairness-aware locality when concurrency drops, load-balanced-under-hits when concurrency spikes — using live signal, not offline tuning.
Treat memory as a hierarchy, not a budget
Eviction is reuse-weighted, not uniform: the prefix every step re-reads is not interchangeable with a one-shot tool result, and the cache stops treating them as such. Memory itself is a hierarchy — HBM, pinned DRAM, NVMe, and an RDMA-reachable pool beyond, orders of magnitude apart in latency and capacity — and different KV blocks belong on different tiers. The engine moves them between tiers on the timescale of a single tool-call gap: system prompts pinned with effectively unbounded retention, a parent context with live subagents reading it pinned until they drain, a long tool-call gap triggering a paired demote-and-recall so the block leaves HBM as the gap opens and is recalled in time for the resume. Across the fleet, a shared KV index dedupes prefixes so the parent is held once, not N times.

Make migration a first-class scheduling primitive
Per-worker tiering is not enough. Where KV lives on the fleet decides whether the next routing decision is a cheap continuation or a multi-second recompute. KV offload demotes blocks down the tier stack when HBM declines to hold them. KV migration moves a live trace's state to a different worker when the routing score changes — on triggers the runtime already observes: load asymmetry, locality decay, an incoming resume on a hot worker. Migration is what makes the stack adaptive rather than just observant. The runtime stops asking who can serve this request and starts asking where should this trace's state live one second from now.
Re-decide continuously
None of the above is a one-time decision. Context-length distributions drift. Burst structure shifts. Tool-call gaps move from milliseconds to minutes. A scheduler whose ranking policy was set yesterday is wrong today. A router whose weights were chosen for one concurrency level over-routes when concurrency drops and thrashes when it spikes. The runtime observes its own fleet and re-allocates scheduling, routing, and KV placement against that signal in flight — no restart, no drain, no operator in the loop.
Standard inference primitives — continuous batching, chunked prefill, disaggregated prefill/decode — all sit underneath this loop. They are necessary; they are not sufficient. What makes the stack work for async AI is the loop above them: continuous re-allocation across the whole fleet.
What dynamic inference opens up
Async AI is the workload that does not fit the current stack. Tasks per dollar - indicating lower JCT and higher fleet throughput, at the same time -lives or dies on whether the runtime can see the trace, follow the cache, work the memory hierarchy, and adapt as the mix moves. That is the contract Impala is built to.
Send us your worst trace
If you are running agents at scale and the inference economics are not where they need to be, send us your worst-performing trace. We will benchmark it on the same setup and show you what dynamic inference does to it.

